Learning to rank for flight itinerary search
Recently, at the Workshop on Recommenders in Tourism (part of ACM RecSys 2017), I had the opportunity to give a keynote where I shared some of our recent experiments in this domain — and particularly, on how we’re applying machine learning within this problem. In this post, I’ll expand on some of the thoughts that I shared there.
A Complex Search Problem
Many of us will have already experienced the pain of searching for an ideal flight — there are so many different factors that come into play. Is this too expensive? Could we get to the airport for this time? Should we stopover somewhere to save some money, or pay a bit more for a direct flight? Should we leave a day earlier and come back a day later? Depending on where you are flying from and trying to fly to, the possibilities may seem endless.
In a recent post, Zsombor described how the Skyscanner app’s flight search result page has evolved over time —it is now moving away from being an infinite list of price-sorted flights and towards being a set of tools (or widgets) that help users navigate the complexity of this choice. While there are many ideas and improvements that we can envisage that will surface information and control, one of the questions that we asked was: can we help users by immediately surfacing the ‘best’ flights? Learning to Rank
In the research literature, sorting ‘items’ (in this case, flight itineraries) using some notion of ‘best’ or ‘relevant’ is known as learning to rank. Applying various forms of machine learning in this problem space has been studied extensively and is increasingly common across various products (e.g., Search at Slack, Venue Search in Foursquare, and Ranking Twitter’s Feed).
The basic premise is that if we had data about items that users think of as relevant to their query — positive examples — and items that users think were not relevant to their query — negative examples — then we can use these to train a machine learning model that can predict the probability that a user will find a flight relevant to their query. In doing so, we have translated the problem of ranking items into a binary regression one (note: there are other methods, such as the pairwise approach to ranking which I do not cover here).
Defining relevance in any context is tricky. Many systems rely on measuring this implicitly, by looking at what items users are clicking on. In the Skyscanner app, though, clicking on a search result is not a very strong signal that users have found what they are looking for — you may simply be clicking on the itinerary to find out a little bit more. A much stronger signal of relevance is the commitment click through to the airline/travel agent’s website to purchase it, which requires multiple actions from the user.

There were a few stages in the journey from the idea of ranking flight search results with machine learning to experiments. We tackled these with two streams of work — offline and online experiments.
Could it work? Offline Experiments
We first refined how we collected data about each user’s search experience; this data was then fed through a pipeline that took care of joining, transforming, and reshaping it into a set of features and a binary relevance score.
Having this kind of historical data allows us to ask what-if kind of questions. What if we had sorted flights in a different way — would the flight that you picked appear closer to the top of your search result list?
Formally, this means conducting a number of offline evaluations. We developed a toolkit to support this work — much like similar open-source tools, this toolkit took care of the basics of conducting a machine learning experiment: splitting the data into training/test and collecting a variety of metrics (e.g., Mean Average Precision and Mean Reciprocal Rank) during each test. We developed our own tool so that we could compare how any machine learning approach compares to a simple baseline: price sorting.
Unsurprisingly, many of our initial experiments did not pay off. Our baseline was proving to be incredibly difficult to beat — perhaps given that all of our data was sourced from users viewing search results ranked this way. We kept on iterating here until we found one set of features that seemed to be doing better than price-sorting, using an incredibly simple model to begin with: logistic regression.
Will it work? An Online Experiment
An open challenge with offline machine learning experiments is understanding how offline metrics correlate with online performance. In other words, just because an algorithm seems to do better than the baseline on historical data, it doesn’t mean that it will do better for users. To validate this, we turned to an online experiment.
To do so, we built all of the remaining parts we needed to run a production experiment. At Skyscanner, this means building components that interact with our data platform and a micro service to serve predictions.
One way to evaluate this approach in an A/B test would be to completely replace the price-sorted list with a new, relevance sorted one. While this approach is being actively explored, the UI that we initially tested was a widget that recommended flights above the price-sorted list.
In the end, we ran an experiment comparing users who were given recommendations using machine learning, users who were given recommendations using aheuristic that only took price and duration into account, and users who were not given any recommendations at all.
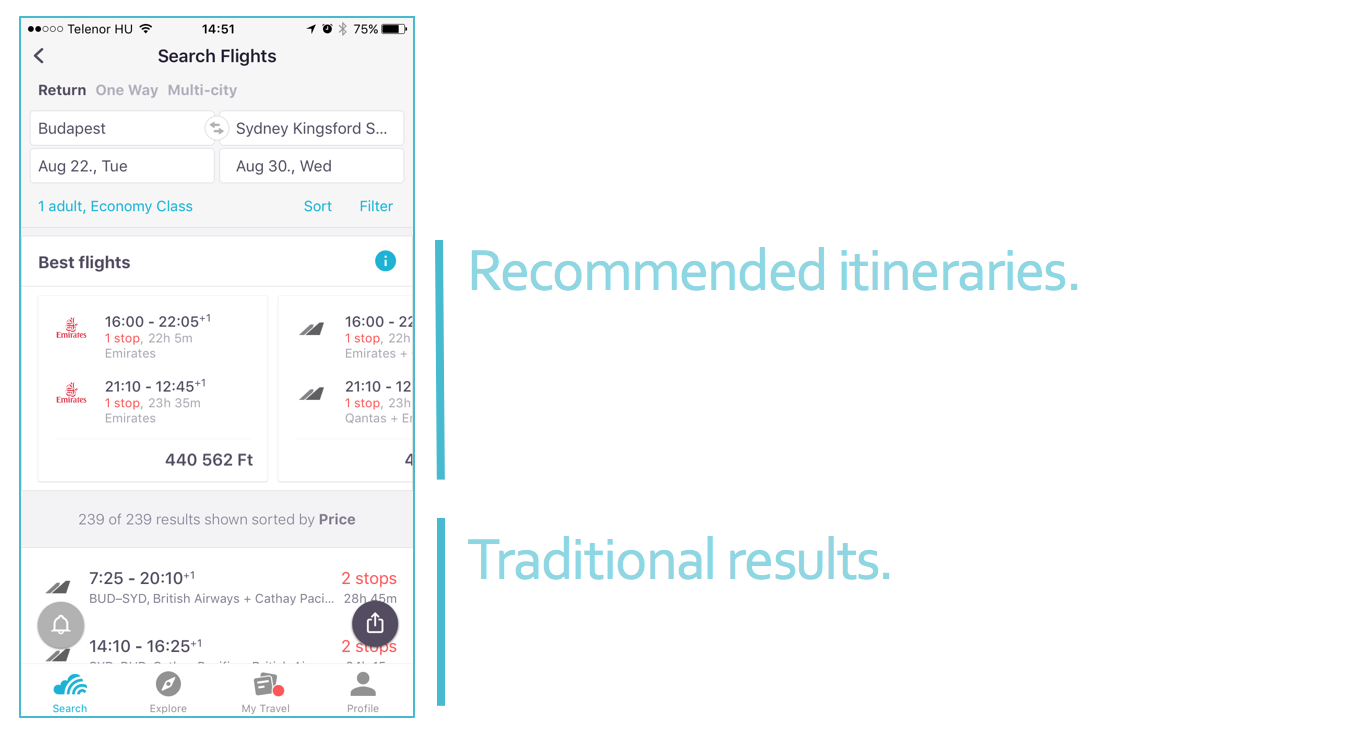
Our First Results: Search Effort and Conversion
As above, we did not evaluate this by looking at clicks — we were not interested in users clicking on a widget. Instead, we first quantified search effort by looking at how often users would filter/resort/re-search for an itinerary in a single session, both when they received flight recommendations and when they didn’t. In this case, we didn’t find any significant differences.
More broadly, though, we were interested in measuring conversion — how often users would purchase a flight that was recommended by the widget versus purchasing a flight that fell below it, in the ‘traditional’ result list. We found evidence of great promise — much to our surprise, this first ranking model drove more purchases into the widget than the rule-based variant.
This experiment is one of many; a lot of the process was about laying the foundation so that we can explore the thousands of hypotheses that using machine learning for flight ranking offers — both offline and online.
There is much more to come in this space at Skyscanner: experiments that focus on the UI, that go across platforms, that test new machine learning models, and on the various widgets that can be built using this approach.